Phoneme Level Lyrics Alignment and Text-Informed Singing Voice Separation
Welcome to the demo website of the paper
Schulze-Forster, K., Doire, C., Richard, G., & Badeau, R. "Phoneme Level Lyrics Alignment and Text-Informed Singing Voice Separation." IEEE/ACM Transactions on Audio, Speech and Language Processing (2021). doi: 10.1109/TASLP.2021.3091817
Audio examples for Figure 5
White noise as audio input
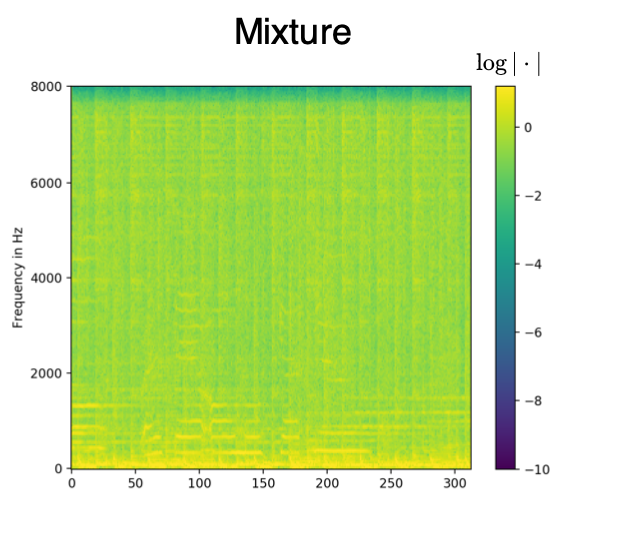
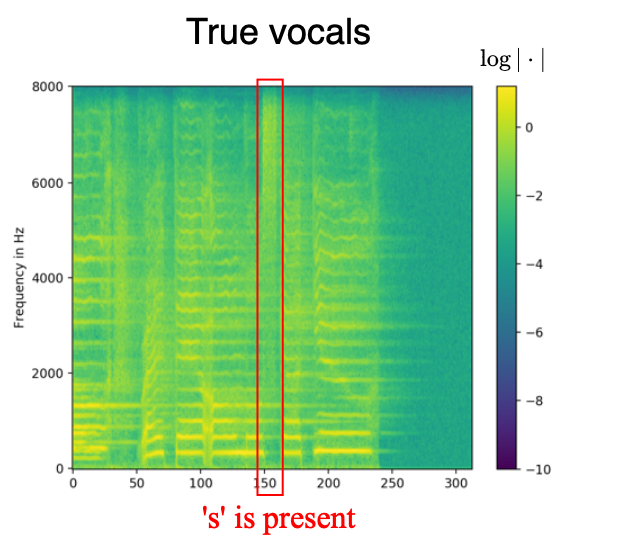
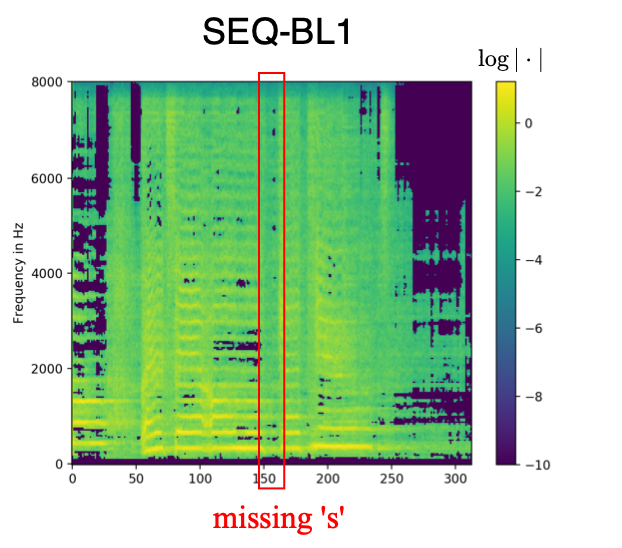
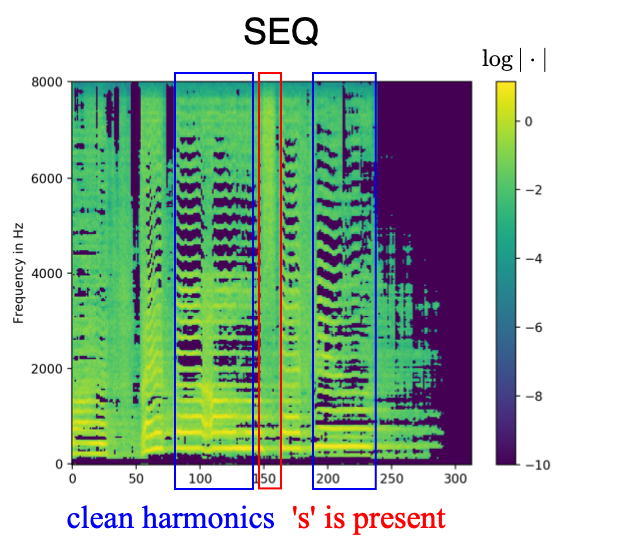
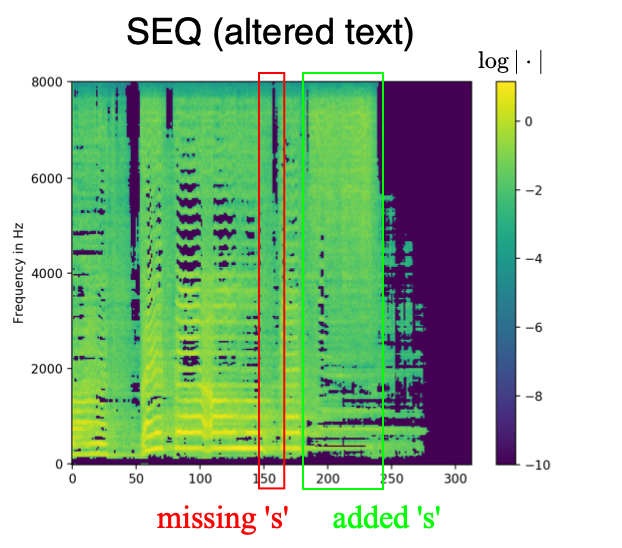
The model SEQ, which was trained with aligned phonemes as side information, shapes white noise inputs according to the given phoneme information. The text examples below are taken from the MUSDB test set. The phonemes have been aligned with the mixture using the model JOINT3 as described in the paper. Therefore, the phoneme duration corresponds to the phoneme duration in the original singing voice signal given accurate alignments. The phonemes are denoted using the 2-letter ARPABET system. The space token is denoted by '>'.
White noise input
Text input
Output
True vocals
> B AH T > SH IY Z > T UW > B L AY N D > T UW > S IY > IH N > M AY > K AA R > (but she's too blind to see in my car)
> T EY K > AE N > AE P AH L > P L IY Z > F R AH M > DH AH > F R AH N T > R OW > (take an apple please from the front row)
> AH N D > AY > K AE N AA T > D IH S AY D > W AH T > IH T > IH Z > T UW > B IY > AH L AY V > (and i cannot decide what it is to be alive)
> DH IH S > L AE F > AH V > R IY Z AH N > W EH N > W IH L > IH T > B R EY K > (this laugh of reason when will it break)
> W EH N EH V ER > Y UW > D IH S AY D > T UW > R AH N > F R AH M > M IY > Y UW > R AH N > M EY K > SH UH R > Y UH R > F AA R > G AO N > Y UW > G AO N > (whenever you decide to run from me you run make sure you're far gone you gone)
Additional audio examples
Mix
True vocals
Category
SEQ-BL1
SEQ-BL2
SEQ
Comment
(c) 2+ singers, 2+ phon.
Backing vocals suppressed through text information
(c) 2+ singers, 2+ phon.
Backing vocals suppressed through text information