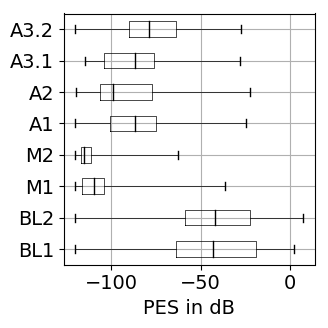
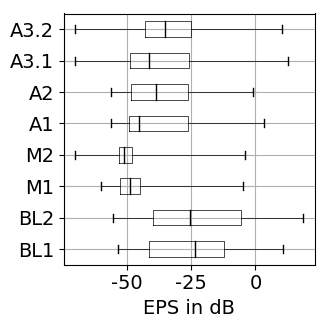
Welcome to the complementary material of the paper. Here you find additional results, audio examples, and a PyTorch implementation of the proposed model. All details about the model architecture, training, and experimental setups are explained in the paper.
Abstract
Prior information about the target source can improve audio source separation quality but is usually not available with the necessary level of audio alignment. This has limited its usability in the past. We propose a separation model that can nevertheless exploit such weak information for the separation task while aligning it on the mixture as a byproduct using an attention mechanism. We demonstrate the capabilities of the model on a singing voice separation task exploiting artificial side information with different levels of expressiveness. Moreover, we highlight an issue with the common separation quality assessment procedure regarding parts where targets or predictions are silent and refine a previous contribution for a more complete evaluation.
Results
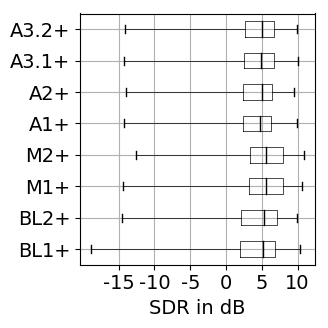
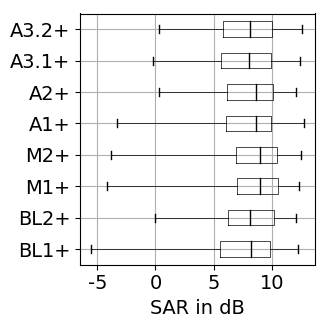
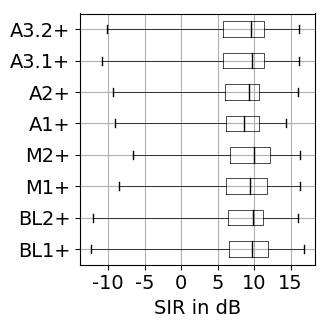
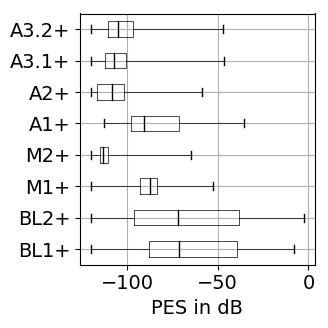
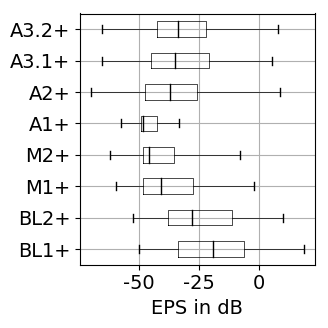
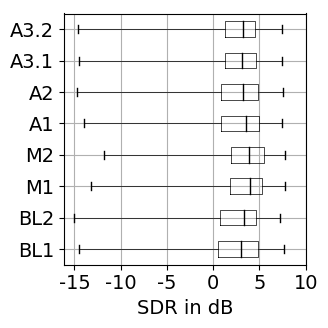
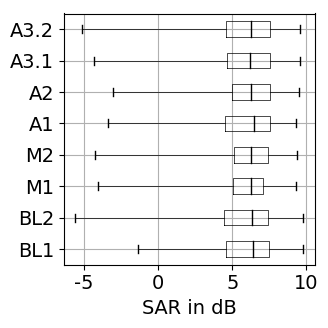
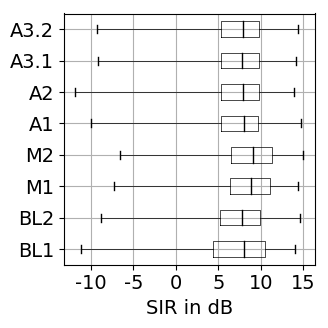
The results for training with additional data (65 rock-pop songs with a total length of 96 minutes) are presented in Figure 1. The results for training only on MUSDB18 [1] tracks as explained in the paper are shown in Figure 2.
Figure 1: Source separation evaluation results for additional training data. For SDR, SAR, SIR higher values are better, while for PES and EPS lower values are better. BL: baseline, M: vocal magnitude side information, A: vocal activity side information. The '+' indicates use of additional training data. Figure 2: Source separation evaluation results for training on 80 songs of MUSDB18. For SDR, SAR, SIR higher values are better, while for PES and EPS lower values are better. BL: baseline, M: vocal magnitude side information, A: vocal activity side information.
Audio Examples
All audio examples are produced with MUSDB18 [1] test tracks.
Track: Schoolboy Fascination Artist: Al James Excerpt: 01m22s - 01m30s
Mixture:
Ground Truth:
BL1:
BL1+:
BL2:
BL2+:
M1:
M1+:
M2:
M2+:
A1:
A1+:
A2:
A2+:
A3.1:
A3.1+:
A3.2:
A3.2+:
Track: We’ll Talk About It All Tonight Artist: Ben Carrigan Excerpt: 02m28s - 02m36s
Mixture:
Ground Truth:
BL1:
BL1+:
BL2:
BL2+:
M1:
M1+:
M2:
M2+:
A1:
A1+:
A2:
A2+:
A3.1:
A3.1+:
A3.2:
A3.2+:
Track: Pray For The Rain Artist: Nerve 9 Excerpt: 04m39s - 04m47s (Vocals are silent!)
Mixture:
Ground Truth:
BL1:
BL1+:
BL2:
BL2+:
M1:
M1+:
M2:
M2+:
A1:
A1+:
A2:
A2+:
A3.1:
A3.1+:
A3.2:
A3.2+:
References
[1] Z. Rafii, A. Liutkus, F.-R. Stöter, S. I. Mimilakis, and R. Bittner, “The MUSDB18 corpus for music separation,” Dec. 2017. Available: https://doi.org/10.5281/zenodo.1117372